
Predictive Analytics with Machine Learning and Databricks Series Pt 1
“The Databricks Console”
Are you one of those IT professionals that wants to become a data scientist? Do you want to find somewhere that you can follow step by step on training a model and doing predictive analytics? I was once that professional too. It’s the inevitable for IT professionals to want to know or learn more. So look no further this blog series will be geared towards getting you started with understanding what components are available within the Databricks console, building and training your first model, and finally reporting off your model with a data visualization tool of choice.
Databricks has evolved over the years and has found a way to be platform agnostic. You can use multiple languages and you can connect to a Databricks cluster from multiple platforms. For this series we will focus on the Microsoft stack as our platform of choice.
To follow along in this series, you are not required to establish a paid account to Databricks unless you want to continue following along once we reach the visualization blog and wish to continue step by step. Databricks has generously offered a community edition which gives you minimal access to using the service for learning opportunities. You can establish a community edition account at:
https://community.cloud.databricks.com/login.html
Familiarizing ourselves with the console is important for ease of navigation. I am going to use Azure however the community edition looks identical.
In azure you want to start by launching a work space.
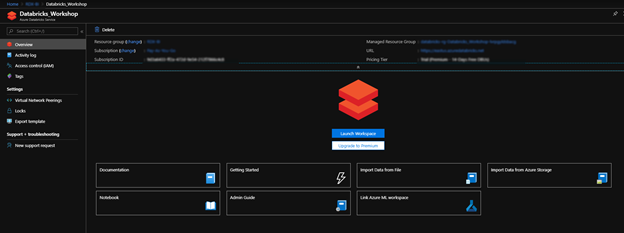
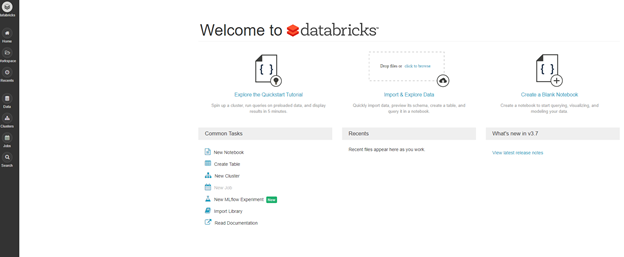
Once you launch your workspace you can see both look the same with slight differences to note that you are in the azure portal:
Azure:

Community Edition:
Let’s take a few minutes and explore Clusters, Workspaces, Notebooks, and Databricks programming languages.
Clusters
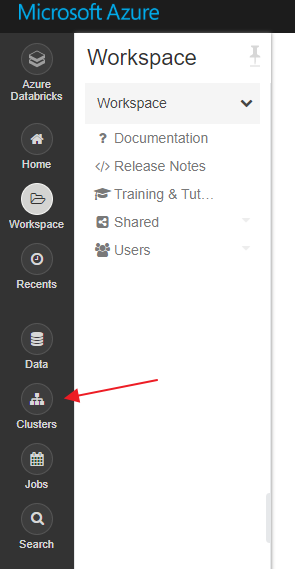
Clusters in not some many words it the engine that does all the work for you. The first thing that you need to run anything in Databricks is a cluster. Through Azure you can use the pay as you go subscription model to help save some money. The good thing about Databricks is it has a pretty well laid out documentation section that gives detailed descriptions of each resource. I have provided the link at the end of the blog for reference purposes.
Workspaces
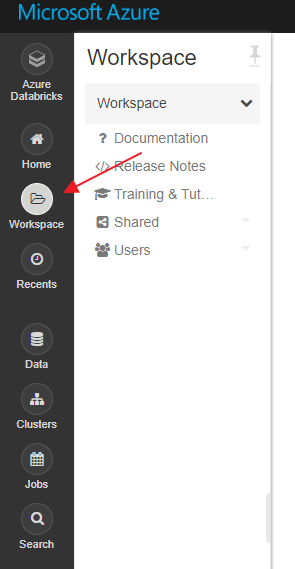
Workspaces are basically an organizational structure. Databricks refers to this as basically your Databricks asset management structure. If you are familiar with the Power BI service, then you can correlate workspaces and how they are used to organize your work.
Notebooks
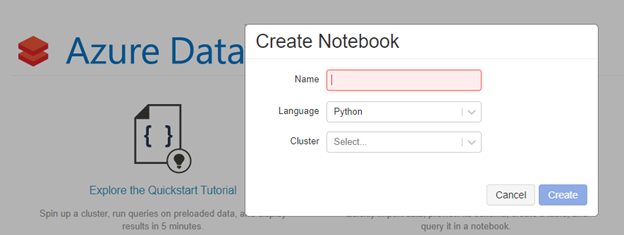
Notebooks is where the magic starts. Notebooks give you the ability to associate the code you will use to train your model to a cluster using Apache Spark. Notebooks is a common term used when programming in R, Python, and Scala. Consider Notebooks as a series of code blocks to logically document and display code results in a sequential order. Remember those high school days when you took notes in a notebook and each chapter’s notes built on the previous chapter? That’s the basic concepts of notebooks in a nutshell.
Languages
Databricks accepts multiple languages for training your model. As you can see below the options are Python, Scala, SQL, and R.
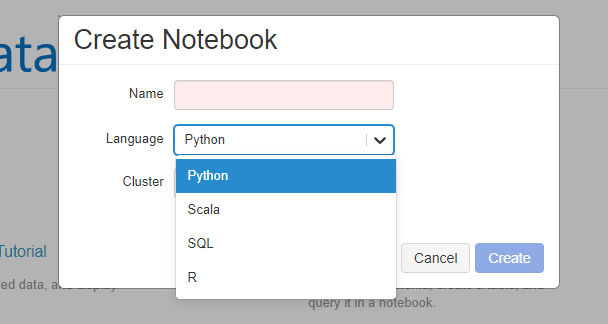
If you are familiar with data mining in any way, then you probably have used either Python or R. Both are data scientist choice of languages for analysis and predictive analytics. SQL is typical structured query language that is used for SQL Server and is the basis of a host of other forms of SQL. Scala on the other hand is an object oriented and functional language that is considered more of a general purpose programming language and runs on JVM (Java Virtual Machine).
Now that we have stepped the basics of the console in part 1 of this series. We will shift our focus to standing up your first cluster and training a predictive analytics model. I have learned over the years that sometimes it’s best to take a step back and understand the concepts and basics before you step feet first into a new endeavor.
Stay tuned for Part 2 of the series in which we will work with clusters and notebooks to train our first predictive analytics model.