
The Life Cycle of a Data Warehouse
All data warehouses should follow a standardized life cycle. Not all life cycles are required to be exactly the same either. In this post we are going to step away from the how-to blogs and step into more of a what you would need to know. Maybe you know what to do but do not understand how to properly plan for the development of a data warehouse? Well if so you have reached the right place to give you an understanding of what it takes. From experience the following steps identify the life cycle and approach from beginning until the end.
- Request or Need
- Requirement Gathering
- Analysis
- Environment Spec and Layout
- Development
- Testing and QA
- Visualization Phase
- Optimization and Stabilization
- Production Go-Live
- Finalizing your Documentation
When you discuss life cycles in IT you think about the evolution of a project or product. I like to look at this as an outer evolution with an inner evolution. Something like this:
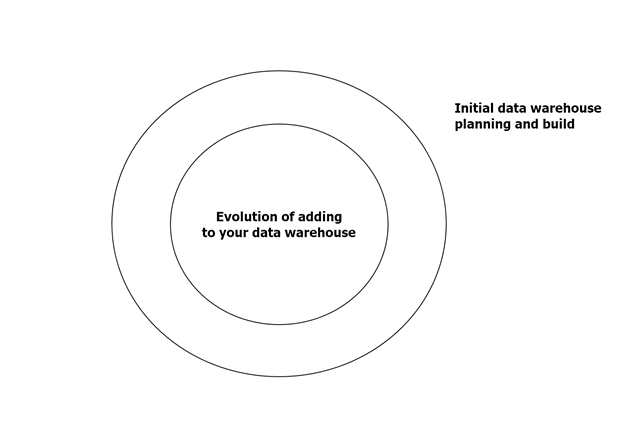
As you can see above you have your outer core and your inner core. The outer is what we would focus as our initial build life cycle. While the inner core uses almost all of the same steps as the outer but doesn’t necessarily always require you to review and make environment specification changes. Now let’s visually take a look at how the process flows
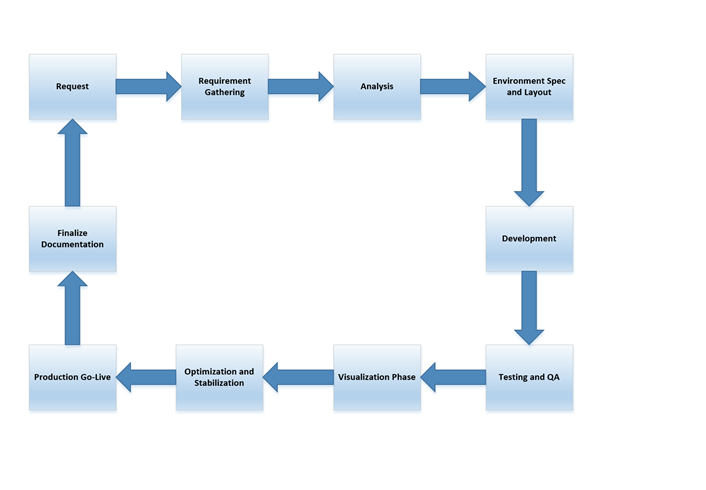
Visually seeing these steps helps but drilling into and identify each of these phases in a data warehouse is also critical.
Request or Need
I know what you are probably thinking. I wouldn’t be here if there wasn’t a request or need. However, a data warehouse build truly does start with someone from somewhere requesting it. Now the important part of a request is knowing that the data warehouse is the right way to go for what the request is. You wouldn’t want to get a request for a report and automatically recommend a data warehouse. Data warehouses cost money and there has to be a true need for it. Maybe the request becomes more of a basic report request. Having the ability to identify the businesses value add of implementing a data warehouse based on the request or need is important. Thus emphasizing the start of the cycle begins here.
Requirement gathering Phase
Part of understanding a request deals with going through a requirement gathering phase. This phase identifies your data points. What can you currently get out of your data and what more do you want? What story will your data tell? During the requirement gathering phase you typically use current reports a customer already has in combination with drafts or mockups of reports the organization would like to have. During this phase you should ask the customer to provide a wish list. This will help establish cost and the effort required. We also have the ability to set expectations by executing a proper requirement gathering phase.
Analysis Phase
let’s start by saying that we only separate this phase from requirement gathering due to the nature or modern data warehousing (SaaS) vs traditional on premises. Also, the complexity of not only analyzing your current data points but analyzing growth and scalability provides justification to separate the analysis phase. Analysis encompasses more of broad range of strategic planning. We look to identify:
- Cost
- What our current data looks like
- ETL vs ELT
- Schema drafts
- On-Premises or Cloud
- Reporting strategy needs
- Real time or streaming analytics needs
- POC’s (show that the choice of technology will work)
- Timelines (goals and milestones)
Environment Specs and Layout
With technology evolving so does the capabilities and ease of standing up an environment. This is where your traditional data warehouse and modern day data warehouse start to take different paths. Traditional data warehouses require you to hone in more on what the specs of the environment may need up front. While your modern data warehouse in the cloud allows for scale on demand.
You should look at things such as data volume and multi-dimensional vs tabular to determine if you need more resource allocation in disk vs RAM. You identify a baseline on CPU’s, OS versions, RDBMS versions. You look at all of these factors and try not to over allocate or build something that you will never need but you still try to identify the minimum with scalability. You take into consideration needing not just a production environment but a testing and QA environment as well.
This is where modern data warehousing and cloud implementations have taken a turn for the better and can save you money. Not only are modern data warehouse built at a scale to handle your traditional data warehouse workloads but also capable of handling big data and parallel processing across compute nodes. What does this mean? You can start with the bare minimum and scale up and down on demand. Not only does this offer the workload needs of data warehousing but also data science workloads. You should take a look at Microsoft’s 2019 release of Azure Synapse. Oh what an excitement in the development and rebirth of azure data warehouse services. No matter which path your organization chooses to take make sure this is documented and including all environment spec changes along the way.
Development Phase
With the environment layout in place we should then migrate over into the development phase. This is where the fun begins. Everything up until the development phase is mainly the job of your data architect. Now we get our hands in there and start coding.
I have said many time ETL and ELT. ETL is a traditional method of getting data transforming it and loading it. With modern day changes you will start to see more staging and data lakes being used. Data is coming from many different sources with different structures that the use case of data lakes, blob storage, and other staging environments has started becoming more prominent. This has transitioned the movement of data more towards an ELT. Let’s extract the data, load it, then use our various tools to transform it into what we need for the data warehouse.
The development phase also looks at the schema and ingests it into what we call the semantic model. We take the aggregations that we identified during the requirement and analysis phases and recreate them in the sematic model. We truly are prepping the data to give us the same data points the organization reported off before and the new data analysis points they want to see going forward.
Testing and QA Phase
Testing and QA is taking the time to cross reference your data points. You want to get your data as accurate as possible before you start report development. This phase incorporates your end users and analyst to ensure that the quality of data is accurate and reportable. You don’t want to show a report and have your upper management point out that your data points are wrong. This will only make them speculate the accuracy of any if not all reports that you provide going forward. Someone who really knows the data and what it takes to get to the accurate reporting values should be heavily involved with this phase. If you have the proper testing and QA phase your visualization phase success rate and adhering to timelines become more obtainable.
Visualization Phase
The visualization phase is not to be taken for granted. This phase is all about the delivery of your work up until this point. Be sure to choose the right visuals to tell your story. A quick google search on how to choose the right visual with your reporting tool of choice will yield plenty of references. One of the points of a data warehouse is to produce aggregations visually and at faster speeds than possible in your traditional OLTP system. Now you’re taking the tool of your choice, using your semantic model, and showing your organization their ROI.
Building a data warehouse is a big project by itself. If your visualization doesn’t appeal to your targeted audience, then in most cases they won’t care about anything else that is produced. The visualization phase is a form of reverse psychology. Think about it the visual is the eye catcher and then the data points are viewed second. Ask a data viz professional what they think and they will explain how important the visualization is.
Optimization and Stabilization
Optimization and stabilization are two different things but truly complement one another when identifying the life cycle of a data warehouse. Although you have created a data warehouse at this point doesn’t mean its optimized for your reporting requests. Here you will begin the task of benchmark testing. Some optimization techniques may include but is not limited to semantic model code rewrites, partitioning, model restructuring, ETL changes, etc. These are points that a developers and architects will collaborate on after speed and resource benchmark testing has been completed.
Once you go through identifying your optimization opportunities you have to stabilize the environment. This task is geared around not only the infrastructure and resizing but also the processes that directly are tied to the environment as a whole such as ETL processes, daily maintenance, backup and recoverability, etc. Once you have stabilized your environment you are ready for your production release.
Production Go-Live
A production cutover and go-live can be an exciting and stressful event. I would suggest practicing as much as possible if you can. Production releases gives you a sense of realizing that your work is being release for everyone to consume and use. The initial build typically can happen at any time of the day. However once that first release as production has been achieved all other updates and request typically happen on a downtime schedule. Sometimes a production release of changes or updates occur in batches. It all depends on the size and complexity of the environment and the type of change. Even production releases don’t always go as planned so don’t get down on yourself just make sure you document a good rollback plan prior to each production release.
Finalizing Documentation
This phase has to be one of the most important phases that does not include any development or analysis. There are so many organizations that do not understand the importance of having your environment documented on all aspects. Finalizing your documentation is like putting the finishing touches on a new product that you created. You should take pride and knowing you have reached the home stretch.
Some look at not finalizing their documentation as some sort of job security. However, it’s really considered as not finishing the job if you think about it logically. You should take pride in your work and make it easy for anyone to follow. Documenting your environment from your source all the way to your ending product shows that your environment flows and runs like a well-oiled machine.
Your documentation should include:
- Environment Specifications
- Data dictionary of the source
- Your ETL/ELT transformation
- Destination data dictionary
- Aggregation definitions
- Semantic modeling description
- Security details
- Job schedules and tested run times
Finalizing your documentation is like telling your own story about your data warehouse project. It really comes down to how detailed you want it to be. The recommendation is to get as detailed as possible because it doesn’t just help you keep track of your environment. It also helps others have the ability to help you keep your environment in good standings. Honestly being someone who has worked over the last nine years at a manages service provider; I can say that the worse part about new customers is inheriting an environment and no one knowing any details about what’s going on except that they know somethings broken.
Hopefully this helps you and your organization understand the life cycle of a data warehouse. It’s not all about let’s get our hands dirty and build something. You truly need to know the life cycle of a data warehouse and what it takes to maintain it overall. The good thing is if you have a good cycle in place for the build then you have a good cycle in place for changes and deployments. Not all cycles have to be the same but the phases outlined above should be considered important to and data warehouse life cycle.